Yiran Xu
I'm a research scientist at Adobe Research. I received my Ph.D. from the University of Maryland, College Park, where I was advised by Prof. Jia-Bin Huang.
My research interests are in computer vision and deep learning, focusing on generative models and their applications, especially in videos.
I've interned at ![]() Google DeepMind,
Google DeepMind,
![]() Adobe Research
and
Adobe Research
and ![]() Snap Research,
where I had the pleasure of collaborating with many
Snap Research,
where I had the pleasure of collaborating with many
![]() Google DeepMind (2024):
Feng Yang,
Yinxiao Li,
Luciano Sbaiz,
Junjie Ke,
Miaosen Wang,
Hang Qi,
Han Zhang,
Jose Lezama,
Ming-Hsuan Yang,
Irfan Essa,
Jesse Berent.
Google DeepMind (2024):
Feng Yang,
Yinxiao Li,
Luciano Sbaiz,
Junjie Ke,
Miaosen Wang,
Hang Qi,
Han Zhang,
Jose Lezama,
Ming-Hsuan Yang,
Irfan Essa,
Jesse Berent.
![]() Adobe Research (2023):
Difan Liu,
Taesung Park,
Richard Zhang,
Yang Zhou,
Eli Shechtman,
Feng Liu.
Adobe Research (2023):
Difan Liu,
Taesung Park,
Richard Zhang,
Yang Zhou,
Eli Shechtman,
Feng Liu.
![]() Adobe Research (2022):
Seoung Wug Oh,
Zhixin Shu,
Cameron Smith.
Adobe Research (2022):
Seoung Wug Oh,
Zhixin Shu,
Cameron Smith.
![]() Snap Research (2021):
Jian Ren,
Zeng Huang,
Menglei Chai,
Kyle Olszewski,
Hsin-Ying Lee,
Sergey Tulyakov.
Snap Research (2021):
Jian Ren,
Zeng Huang,
Menglei Chai,
Kyle Olszewski,
Hsin-Ying Lee,
Sergey Tulyakov.

Publications
Yicong Hong*, Yiqun Mei*, Chongjian Ge*, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, Kalyan Sunkavalli, Feng Liu, Zhengqi Li, Hao Tan
*: equal contribution
Technical Report, 2025
TL;DR: RELIC is an interactive video world model that can generate 20s videos in 16FPS with long-horizon memory.
Project Page / Paper /
@article{hong2025relicinteractivevideoworld,
author = {Yicong Hong* and Yiqun Mei* and Chongjian Ge* and Yiran Xu and Yang Zhou and Sai Bi and Yannick Hold-Geoffroy and Mike Roberts and Matthew Fisher and Eli Shechtman and Kalyan Sunkavalli and Feng Liu and Zhengqi Li and Hao Tan},
title = {RELIC: Interactive Video World Model with Long-Horizon Memory},
journal = {Technical Report},
year = {2025},
}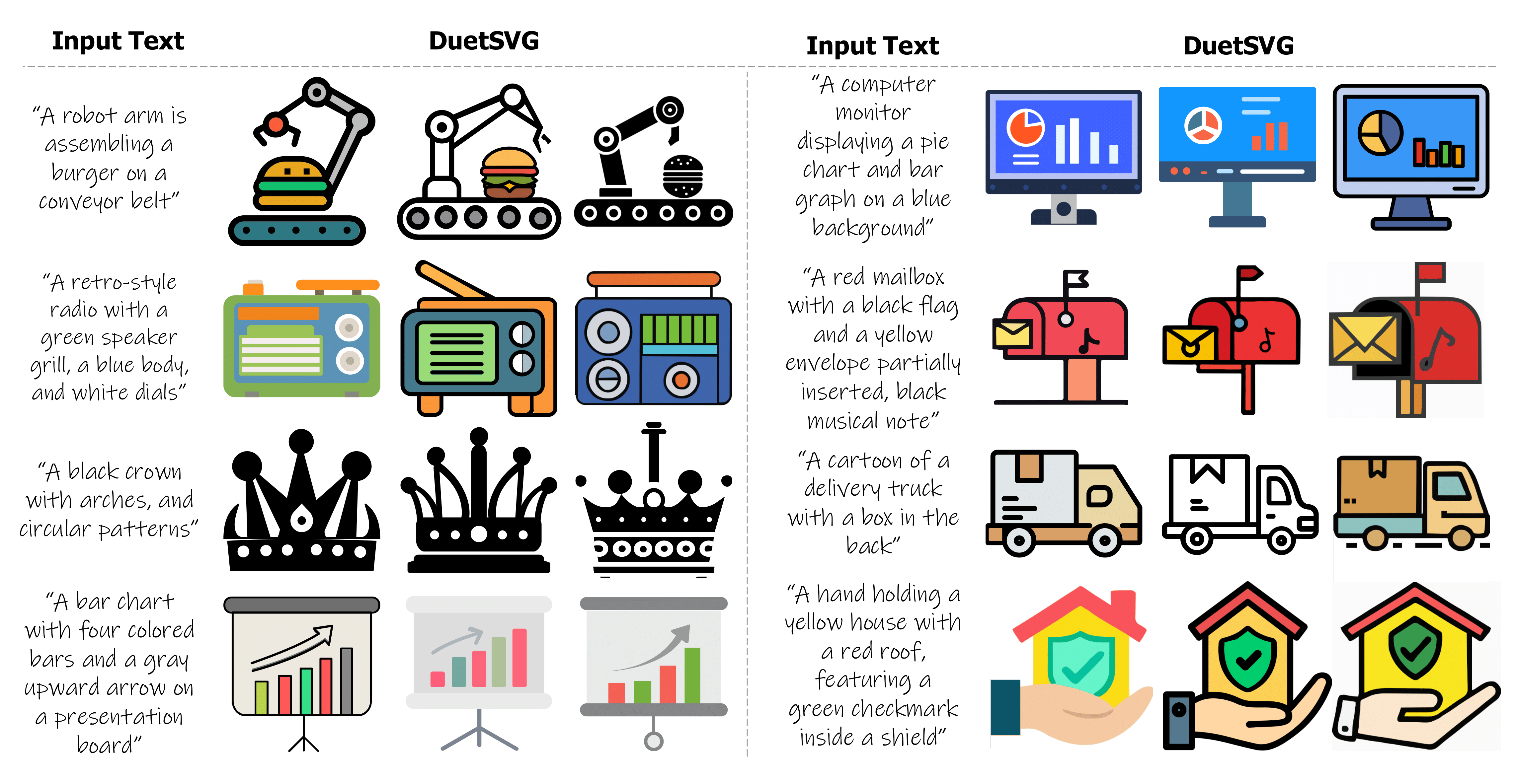
Peiying Zhang, Nanxuan Zhao, Matthew Fisher, Yiran Xu, Jing Liao, Difan Liu
CVPR, 2026
TL;DR: DuetSVG is a unified multimodal for both SVG and raster image generation/editing.
Project Page / Paper /
@inproceedings{zhang2025duetsvg,
author = {Peiying Zhang and Nanxuan Zhao and Matthew Fisher and Yiran Xu and Jing Liao and Difan Liu},
title = {DuetSVG: Unified Multimodal SVG Generation with Internal Visual Guidance},
booktitle = {CVPR},
year = {2026},
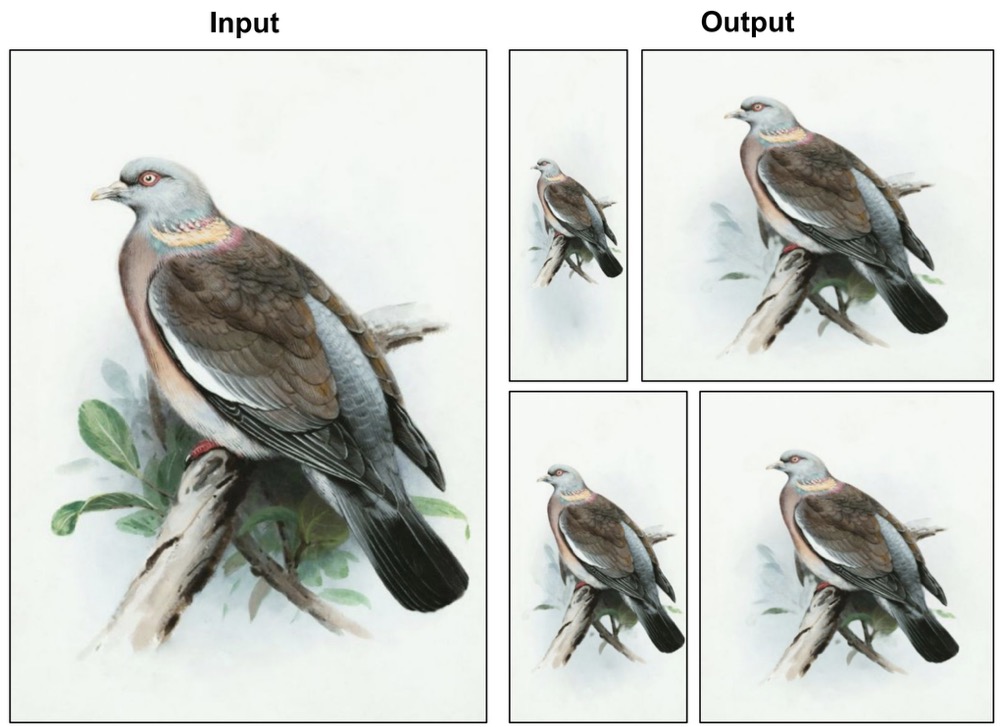
}Subin Kim, Sangwoo Mo, Mamshad Nayeem Rizve, Yiran Xu, Difan Liu, Jinwoo Shin, Tobias Hinz
CVPR, 2026
TL;DR: We rethink prompt design for inference-time scaling in text-to-visual generation.
Project Page / Paper /
@inproceedings{kim2025rethinking,
author = {Subin Kim and Sangwoo Mo and Mamshad Nayeem Rizve and Yiran Xu and Difan Liu and Jinwoo Shin and Tobias Hinz},
title = {Rethinking Prompt Design for Inference-time Scaling in Text-to-Visual Generation},
booktitle = {CVPR},
year = {2026},
}Ting-Hsuan Liao, Haowen Liu, Yiran Xu, Songwei Ge, Gengshan Yang, Jia-Bin Huang
SIGGRAPH ASIA, 2025
TL;DR: PAD3R reconstructs a dynamic 3D object from a single casual video.
Project Page / Paper /
@article{liao2025pad3r,
author = {Ting-Hsuan Liao and Haowen Liu and Yiran Xu and Songwei Ge and Gengshan Yang and Jia-Bin Huang},
title = {PAD3R: Pose-Aware Dynamic 3D Reconstruction from Casual Videos},
journal = {SIGGRAPH ASIA},
year = {2025},
}Yiran Xu, Taesung Park, Richard Zhang, Yang Zhou, Eli Shechtman, Feng Liu, Jia-Bin Huang, Difan Liu
CVPR, 2025
TL;DR: VideoGigaGAN is a Video Super-Resolution (VSR) method capable of upscaling videos by up to 8x with fine-grained details.
Project Page / Paper / Supplemental / Media Coverage /
@inproceedings{xu2024videogigagan,
author = {Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu},
title = {VideoGigaGAN: Towards Detail-rich Video Super-Resolution},
booktitle = {CVPR},
year = {2025},
}
Yiran Xu, Siqi Xie, Zhuofang Li, Harris Shadmany, Yinxiao Li, Luciano Sbaiz, Miaosen Wang, Junjie Ke, Jose Lezama, Hang Qi, Han Zhang, Jesse Berent, Ming-Hsuan Yang, Irfan Essa, Jia-Bin Huang, Feng Yang
arXiv, 2025
TL;DR: HALO is a human-aligned end-to-end image retargeting method that leverages layered transformations for natural image retargeting.
Project Page / Paper /
@article{xu2025halo,
author = {Yiran Xu and Siqi Xie and Zhuofang Li and Harris Shadmany and Yinxiao Li and Luciano Sbaiz and Miaosen Wang and Junjie Ke and Jose Lezama and Hang Qi and Han Zhang and Jesse Berent and Ming-Hsuan Yang and Irfan Essa and Jia-Bin Huang and Feng Yang},
title = {HALO: Human-Aligned End-to-end Image Retargeting with Layered Transformations},
journal = {arXiv},
year = {2025},
}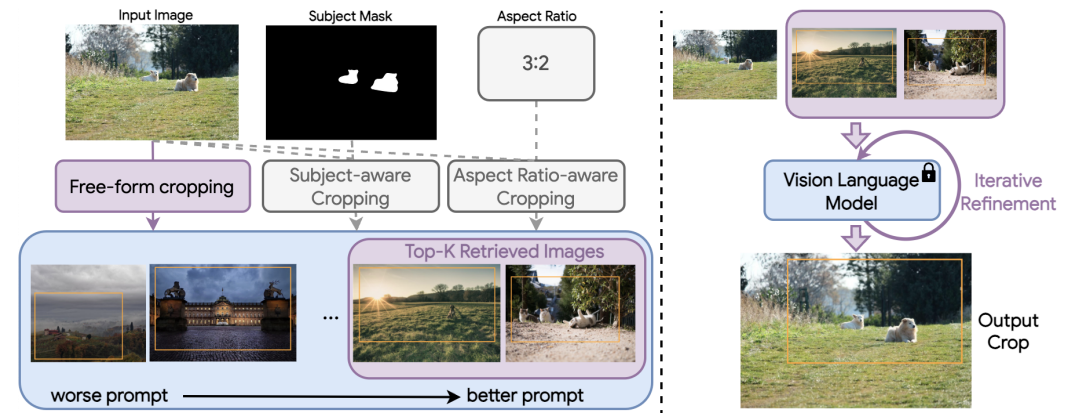
Seung Hyun Lee*, Jijun Jiang*, Yiran Xu*, Zhuofang Li*, Junjie Ke, Yinxiao Li, Junfeng He, Steven Hickson, Katie Datsenko, Sangpil Kim, Ming-Hsuan Yang, Irfan Essa, Feng Yang
*: equal contribution
CVPR, 2025
TL;DR: Cropper leverages VLMs for image cropping through in-context learning.
Project Page / Paper /
@inproceedings{lee2025cropper,
author = {Seung Hyun Lee* and Jijun Jiang* and Yiran Xu* and Zhuofang Li* and Junjie Ke and Yinxiao Li and Junfeng He and Steven Hickson and Katie Datsenko and Sangpil Kim and Ming-Hsuan Yang and Irfan Essa and Feng Yang},
title = {Cropper: Vision-Language Model for Image Cropping through In-Context Learning},
booktitle = {CVPR},
year = {2025},
}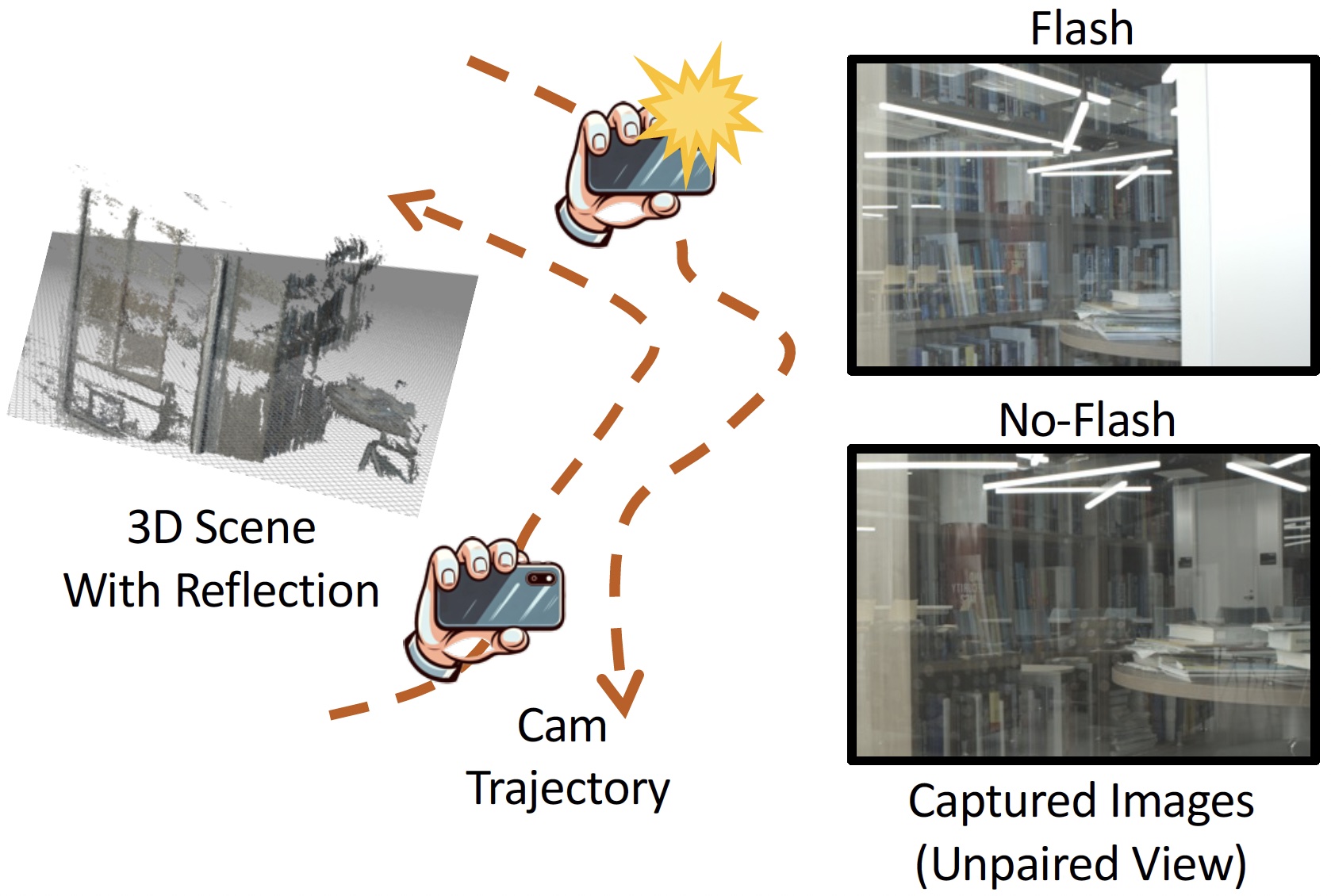
Mingyang Xie, Haoming Cai, Sachin Shah, Yiran Xu, Brandon Y Feng, Jia-Bin Huang, Christopher A Metzler
ECCV, 2024
TL;DR: Flash-Splat is a 3D reflection removal method that leverages flash cues and Gaussian splats for robust performance.
Project Page / Paper /
@inproceedings{xie2024flashsplat,
author = {Mingyang Xie and Haoming Cai and Sachin Shah and Yiran Xu and Brandon Y Feng and Jia-Bin Huang and Christopher A Metzler},
title = {Flash-Splat: 3D Reflection Removal with Flash Cues and Gaussian Splats},
booktitle = {ECCV},
year = {2024},
}Yiran Xu, Zhixin Shu, Cameron Smith, Seoung Wug Oh, Jia-Bin Huang
CVPR, 2024
TL;DR: In-N-Out is a 3D GAN inversion method that decomposes the input into two components, enabling effective inversion for Out-of-Distribution (OOD) data.
Project Page / Paper / Supplemental /
@inproceedings{xu2024innout,
author = {Yiran Xu and Zhixin Shu and Cameron Smith and Seoung Wug Oh and Jia-Bin Huang},
title = {In-N-Out: Faithful 3D GAN Inversion with Volumetric Decomposition for Face Editing},
booktitle = {CVPR},
year = {2024},
}
Yi-Ling Qiao, Alexander Gao, Yiran Xu, Yue Feng, Jia-Bin Huang, Ming Lin
ICCV, 2023
TL;DR: DMRF is a hybrid 3D representation that facilitates physical simulations based on NeRFs
Project Page / Paper /
@inproceedings{qiao2023dynamic,
author = {Yi-Ling Qiao and Alexander Gao and Yiran Xu and Yue Feng and Jia-Bin Huang and Ming Lin},
title = {Dynamic Mesh-aware Radiance Fields},
booktitle = {ICCV},
year = {2023},
}
Ting-Hsuan Liao, Songwei Ge, Yiran Xu, Yao-Chih Lee, Badour AlBahar, Jia-Bin Huang
arXiv, 2023
TL;DR: We leverage latent diffusion priors for multiple text-driven visual synthesis tasks.
Project Page / Paper /
@article{liao2023text,
author = {Ting-Hsuan Liao and Songwei Ge and Yiran Xu and Yao-Chih Lee and Badour AlBahar and Jia-Bin Huang},
title = {Text-driven Visual Synthesis with Latent Diffusion Prior},
journal = {arXiv},
year = {2023},
}
Yiran Xu, Badour AlBahar, Jia-Bin Huang
ECCV, 2022
TL;DR: We propose a flow-based video editing method that enables semantic manipulation with temporal consistency.
Project Page / Paper /
@inproceedings{xu2022temporally,
author = {Yiran Xu and Badour AlBahar and Jia-Bin Huang},
title = {Temporally Consistent Semantic Video Editing},
booktitle = {ECCV},
year = {2022},
}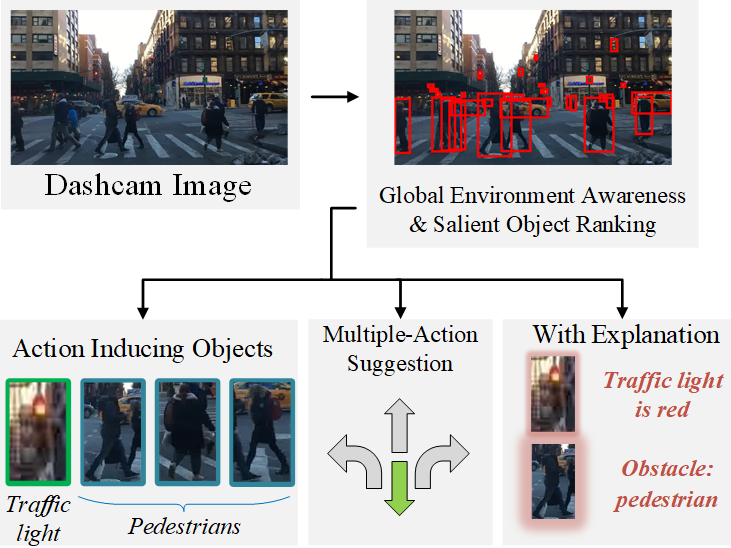
Yiran Xu, Xiaoyin Yang, Lihang Gong, Hsuan-Chu Lin, Tz-Ying Wu, Yunsheng Li, Nuno Vasconcelos
CVPR, 2020
TL;DR: We propose an explainable decision-making framework for autonomous vehicles.
Project Page / Paper /
@inproceedings{xu2020explainable,
author = {Yiran Xu and Xiaoyin Yang and Lihang Gong and Hsuan-Chu Lin and Tz-Ying Wu and Yunsheng Li and Nuno Vasconcelos},
title = {Explainable Object-Induced Action Decision for Autonomous Vehicles},
booktitle = {CVPR},
year = {2020},
}Service
Reviewer for CVPR'2022-2024, ICCV'2021-2023, ECCV'2022-2024, NeurIPS'2023, ICLR'2024, ICML'2024, WACV'2023-2024, ACCV'2024.Miscellaneous
My Chinese name is 许亦冉. I was born in Hengyang, China, also known as the “Wild Goose City” (雁城). According to local tales, geese migrating south never go beyond Hengyang because they find the warmest weather here.
I have two cats, Bai (白) and Chelle (锈). They are important members who keep me company during my PhD journey.
{kind=link}
{kind=link}
I started working on computer vision because I wanted to build a makeup machine for my wife. Well...maybe not that simple.
I'm also a newbie in photography. Feel free to check out some of my photos!